

We recently announced the release of NLU 3.0. In that post, we covered the benefits that come with the update, including enhanced detection and coverage. In this post, we’ll look at why we made the updates and how we did it. Let’s start with the why.
Remove constraints and close gaps
The previous engine was trained mostly on real-world malicious and benign emails. While extensive, this dataset couldn’t possibly cover every novel phish or emerging attacker trick. Edge cases or less common linguistic patterns might be under-represented, making the model less confident or accurate. This data limitation meant NLU could be brittle when faced with paraphrased or evolving attack language – a gap attackers are increasingly exploiting.
Unify context
Previously, NLU’s key tasks each had a separate model. One model for Intent Classification, one for Named Entity Recognition (NER), and another for Topic Modeling. Each task provided useful signals (e.g. detecting an “Urgent Request” intent or extracting names of people/companies from text), but operating these in isolation meant we weren’t fully leveraging the shared context and limiting the system’s overall intelligence.
Accelerate feature iteration
Adding a new detection capability (e.g., PII detection) meant training a separate model or significantly re-training the existing one. This process required time and ML expertise, slowing our response to new threat trends. We needed a more agile and extensible NLU framework that could grow quickly without starting from scratch each time.
Updates in NLU 3.0
NLU 3.0 is a leap forward on multiple fronts. Here are the upgrades we’ll dive deeper into:
- Synthetic data augmentation with GenAI
- Unified multi-head architecture for multi-task NLU
- Modular heads for rapid expansion of NLU capabilities
Synthetic data augmentation with GenAI
As with our previous version of NLU, we used LLMs to generate massive amounts of synthetic emails (based on real attacks) for training. We feed anonymized real attack emails – stripped of any sensitive details – into our in-house generative models to create realistic variations of phishing content, the same way attackers are. By producing countless permutations of known scams, we can anticipate the tricks attackers haven’t yet tried, injecting fresh examples into our training pipeline.
In our internal evaluations, this approach paid dividends. For instance, an AI-fabricated BEC email with polite, non-urgent wording (designed to evade urgency detectors) was correctly flagged by the upgraded NLU, whereas a prior version might have overlooked it. By transforming GenAI from an adversary tool into a defensive asset, we ensure our models stay a step ahead of attackers.
Unified multi-head architecture for multi-task NLU
We redesigned the NLU engine into a multi-head architecture – essentially one powerful brain with multiple “heads” that each handle a specific analysis task. Instead of maintaining separate models or sequential processes for intent, entities, topics, etc., we now feed the email through one shared model and branch out to several outputs.
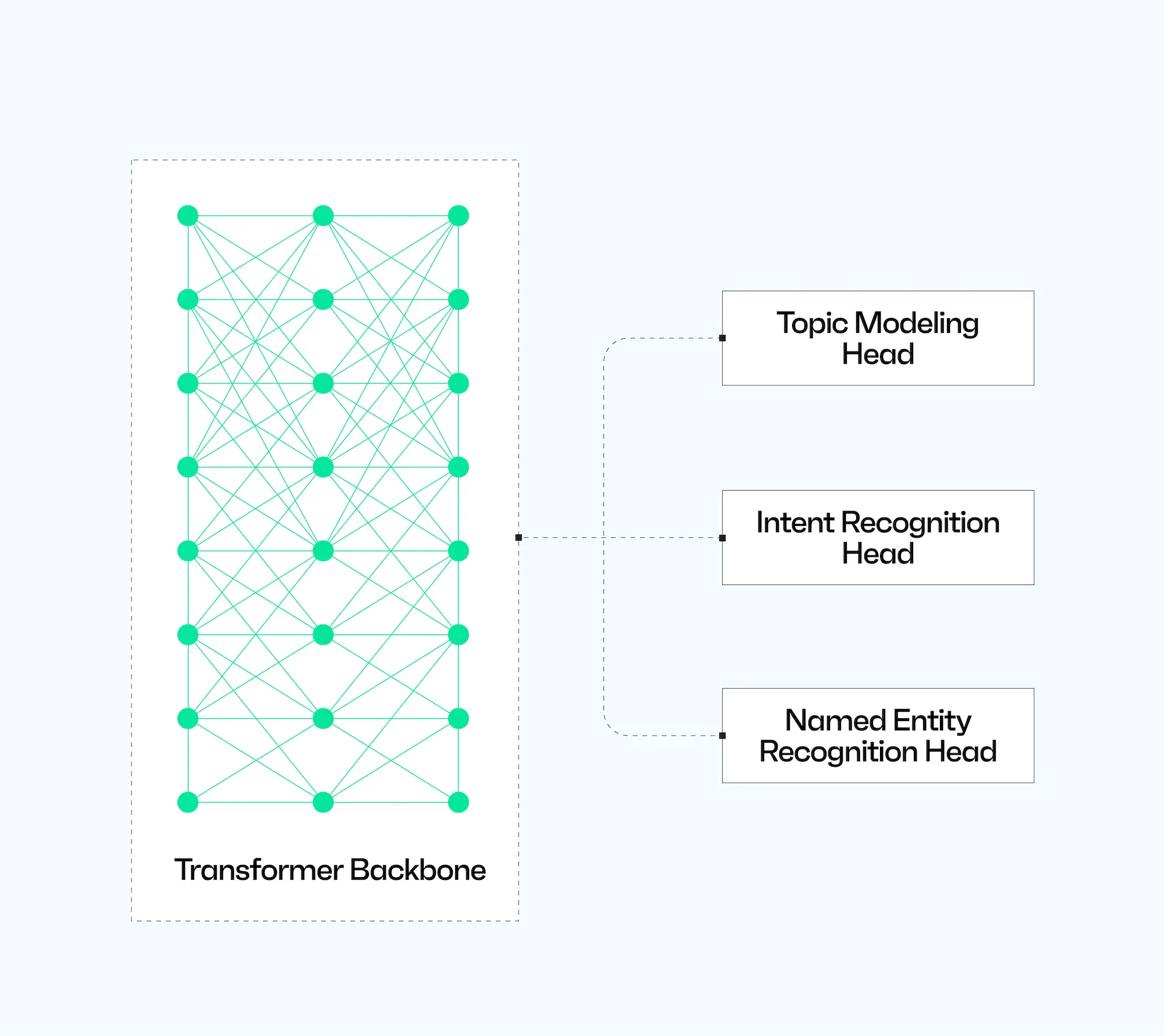
This architecture means all NLU tasks are informed by the same underlying comprehension of the email. The model doesn’t just determine intent in isolation; it learns to do so in context while also recognizing entities and topics. A major benefit of the multi-head approach is shared context. Because the tasks share the same base model representations, they inherently share information. If the NER head learns to recognize the names of banks and payment terms, that knowledge is reflected in the base model’s weights – which in turn helps the topic head better identify a “Financial Communications” topic. In our tests, this cross-pollination improved accuracy for individual tasks compared to training each task alone. TL;DR, this NLU engine develops a richer overall picture of each email.
Another plus is that when tasks share context, outputs tend to be more consistent. If the intent head says “Callback Phishing” and the topic head says “Financial Communications” and “Purchase Orders”, the consistency increases confidence in the verdict. All these pieces reinforce the story of a probable attack, making it clearer and more convincing to a human reviewer and downstream models like Attack Score.
The multi-head setup is computationally efficient, too. With NLU 2.0, if we wanted to extract entities and classify intent, we’d run two separate analyses over the email text. Now, one pass through the transformer gives us all the answers at once. This reduces latency and ensures consistency across tasks.
Finally, this unified design lays a solid foundation to keep adding new tools (heads) without increasing complexity while building off of a holistic understanding of email from the base model.
Modular heads for rapid expansion of NLU capabilities
Perhaps the most exciting aspect of our upgraded NLU is how quickly we can roll out new capabilities. Now, to detect a new type of content or behavior, we can simply attach another head to the shared model, feed it some training data (real and synthetic), and voilà – a new NLU skill is born. The base model already handles much of the heavy lifting (language understanding), so the new head just learns to map that understanding to the new labels of interest.
Because we don’t need to train a whole new model from scratch, we can iterate quickly. Using transfer learning on a shared backbone means that even relatively small datasets, supplemented with synthetic examples, yield high-performing classifiers in a significantly shorter amount of time.
Did (NL)U enjoy this?
We hope you found this post informative. Our Machine Learning team is always improving our models, and these updates to our model, architecture, and training approach mean we’ll be able to move faster than ever. In many cases, faster than attackers.
If you have any questions or comments, drop them into our Sublime Community Slack, drop a line on Linkedin, or send us a Tweet on X.
Get the latest
Sublime releases, detections, blogs, events, and more directly to your inbox.
.svg)



.avif)
