
.png)
Sublime is growing faster than ever, and as we do, we’re taking on larger and larger enterprise customers. These enterprises have massive amounts of mailboxes and we need to be extremely confident that our platform can handle the load before onboarding. That means we need our load testing framework to be able to scale beyond our Sales team’s wildest dreams.
When we initially evaluated tools that would allow us to test at enterprise scale (tools like k6, Gatling, JMeter, and other commercial platforms), we found that none could simulate realistic email provider behavior. Those tools couldn’t mock Google Workspace or Microsoft 365 APIs, handle EML file transformations at scale, or generate realistic email addresses that trigger the correct platform behavior. Additionally, if tools offered extensibility to add that functionality ourselves, it created enough work to cancel out the benefits of buying instead of building.
So instead, we built Mjölnir, a load testing framework purpose-built for email security platforms. We named it after Thor’s hammer because we needed it to drop some thunder on our infrastructure.

In this post, we’ll take a look at how we built Mjölnir, walking through the technical challenges we faced and the algorithms we developed to solve them. We’ll cover:
- The pipeline architecture that powers Mjölnir
- Optimized email address storage
- Realistic email address generation
- Results from load tests
The pipeline architecture
We architected Mjölnir as a producer/consumer pipeline that cleanly separates email preparation from email sending:
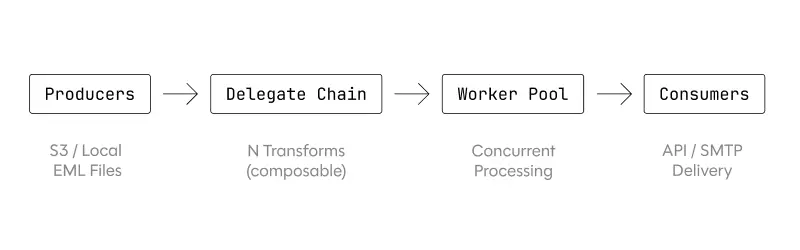
Producers stream EML files from S3 or local storage using io.Reader interfaces. Rather than loading entire files into memory, we parse headers and wrap the body as a reader to keep memory usage constant regardless of message size. This matters when queuing tens of thousands of emails: a naive approach would exhaust memory long before the test completes.
A delegate chain sits between producers and the worker pool. Each delegate implements the same interface and can mutate messages before passing them along. They can alias email addresses, assign message types (inbound/outbound/internal), rewrite headers, and control mailbox cardinality. We can compose any number of delegates to build complex transformations from simple, testable units.
This decoupling of preparation from sending has a subtle but important benefit: timing accuracy. By queuing fully-prepared messages into the worker pool, the configured delay between sends measures actual send intervals – not preparation time plus send time. When we configure 100ms between messages with 10ms jitter, we get precisely that, regardless of how long EML parsing or transformation takes.
Realistic email address generation
Our initial approach used random alphanumeric strings for email addresses because they’re simple to generate and guaranteed to be unique. This created an unexpected problem, though, because random addresses returned test results that were not representative of production traffic. Realistic email addresses generally follow common patterns and rarely are they truly random.
Sublime uses email grouping to cluster related messages for faster, more efficient triage. Since grouping looks at the message as a whole, we can cause additional groups by varying many fields in minor ways or by varying a few fields, like sender address, in significant ways. To make sure email addresses were representative of real traffic, we replaced random strings with a realistic email generator that combines:
- A pool of ~150 first names and ~175 last names
- Different email pattern formats (
firstname.lastname,f.last,first_last, etc.) - Non-resolving test domains (
.test,.example,.localhost)
The result: collision rates under 0.08% at 1 million email addresses, while maintaining realistic patterns.
The mailbox multiplier
Enterprise customers don’t have dozens of mailboxes – they have hundreds of thousands. Testing at that scale with a small corpus of EML files requires multiplying the effective mailbox count.
One of our delegates solves this by mapping original email addresses to N aliases using a ring buffer. A corpus with 100 unique senders and recipients can simulate 100,000 mailboxes with a multiplier of 1,000. Each alias maps deterministically to the original, ensuring consistent behavior across test runs.
Another delegate handles message type assignment. Real organizations don’t receive 100% inbound email, but there’s a mix that varies by industry and company size. The message type delegate assigns inbound, outbound, or internal classification based on configured ratios, enabling realistic traffic distribution. Since delegates compose, we can chain the multiplier with the type assigner with any other transforms we need and each can operate on the output of the previous.
The multiplier delegate creates a challenge. It needs to maintain a consistent mapping from original address to generated alias. When alice@company.com appears in multiple messages within a corpus iteration, it must map to the same alias every time, otherwise message threads and reply chains break. But between iterations, we need fresh aliases to avoid duplicate mailboxes. This means holding millions of address mappings in memory simultaneously.
Suffix-compressed radix trees for email addresses
The alias mapping needs an efficient backing structure when managing millions of email addresses during load tests. Consider 1 million addresses with 10-character usernames and 12-character domains (like @company.com) across 5 unique domains. Storing them as strings costs 22 MB (22 bytes per address). Traditional prefix trees (tries) compress strings that share common prefixes. But email addresses share suffixes more than prefixes since everyone at a company shares a domain, but usernames vary wildly.
We implemented a suffix-compressed radix tree that compresses from the right side of email addresses instead of the left:
For addresses like alice@company.com, bob@company.com, charlie@company.com, carol@foo.com, and dan@foo.com, our suffix tree stores .com once, branches to @company and @foo, then stores each username at the leaves.
This reduces memory consumption significantly when domain entropy is much lower than username entropy, which is typical of real email distributions. Each username is stored once (10 MB), the TLD once (4 bytes), and each domain prefix once (40 bytes for 5 domains), to consume roughly 10 MB total for a 55% reduction over strings.
We pair the radix tree with an arena allocator to reduce GC pressure. In Go, each heap allocation eventually requires garbage collection, and allocating millions of tree nodes creates substantial GC overhead. An arena allocator pre-allocates a large, contiguous block of memory and hands out chunks sequentially. Nodes allocated this way don’t create individual GC tracking overhead, meaning that when the test completes, we free the entire arena in one operation rather than collecting millions of small objects.
Worker pool with delay and jitter
Real email traffic is bursty in ways that can overwhelm unprepared systems. Monday morning brings a surge as employees clear weekend backlogs. A single message to a distribution group fans out to hundreds or thousands of individual deliveries. Outside of normal bursts, there are also malicious ones like email bombs, that can send hundreds or thousands of messages to an inbox over a short period of time.
If these spikes exceed processing capacity, problems cascade. Queues back up. Database load spikes. Processing latency climbs from milliseconds to seconds, then minutes. The platform needs to handle these scenarios gracefully, shedding non-critical load, scaling horizontally, and recovering once the spike passes.
Our worker pool implementation supports configurable delay between tasks with random jitter to simulate these realistic traffic patterns.
The pool uses Go 1.23+ features extensively, including the new two-value iterator type (iter.Seq2) which lets callers range over results as they complete rather than blocking on a channel or accumulating into a slice. This streaming approach keeps memory bounded even when processing millions of messages.
Delay and jitter are specified per test run, enabling stress tests (constant high load), spike tests (sudden bursts), and soak tests (sustained moderate load over hours).
Results from load tests
We’ve used Mjölnir to validate several critical platform capabilities:
Inline processing
We ran sustained load tests sending emails through our inline SMTP pipeline for over an hour. CPU load on our processing services reached around 75%, which is well within acceptable bounds.
When we scaled to 5x the message volume, we saw minimal sub-linear impact to heap size and garbage collection, meaning the system handled the increase gracefully. There were no failures, no degradation, and interestingly, processing latency was actually lower during sustained load than during idle periods. This was likely due to warmed caches and connection pools.
User reports
We stress-tested our user reports integration with deferred ingestion at ~23 queries per second, pushing 8,000+ emails through the async pipeline. The architecture handled enterprise-scale load with comfortable headroom.
Scaling strategies
We’re actively using Mjölnir to evaluate new scaling approaches for our platform. Having a reliable way to generate realistic loads on-demand lets us test infrastructure changes in isolation before they reach production. This lets us easily compare different configurations, validate capacity planning assumptions, and build confidence in our scaling decisions.
Surprise! During development, we found that consumer ISPs block outbound traffic on port 25 by default as a spam prevention measure. This meant our engineers couldn’t run inline SMTP load tests from their laptops against remote platforms. The tests worked fine against local clusters but silently failed against staging environments (womp womp). The fix was to deploy Mjölnir within the target VPC or using cloud instances with port 25 restrictions lifted.
Adding mockups
Mjölnir has already helped our testing efforts a great deal, and it will continue to evolve as our needs grow. For example, we’re currently adding more support for mocking Google Workspace and Microsoft 365 APIs. Fortunately, the producer/consumer architecture makes these extensions straightforward and new consumers and delegates slot in without disrupting existing functionality.
Purpose-built load testing FTW
The gap between generic load testing and email security testing isn’t marginal – it spans protocol support, API behavior simulation, and domain-specific requirements. Because of that gap, our only path forward was to build exactly what we needed.
Building load testing infrastructure for email security required solving problems that generic tools can’t address: realistic email generation at scale, memory-efficient address management, and flexible message transformation pipelines. Mjölnir’s architecture, suffix-compressed radix trees, and composable delegate system give us confidence that our platform can handle enterprise scale before we onboard those customers.
If you enjoyed this post, send us your questions and comments over social (LinkedIn, X). And if this is the type of challenge you like tackling, get in touch with our Engineering team.
Get the latest
Sublime releases, detections, blogs, events, and more directly to your inbox.
.svg)



.avif)
