
If you've spent any time in AI circles recently, you've seen the explosion of debate around "evals." The conversation is circling a critical point: generic, off-the-shelf evaluations are often viewed as useless, as they measure abstract concepts like faithfulness or helpfulness, which essentially results in measuring noise. However, the consensus is clear: vendors must strive to deliver evaluations that align with the problems their agents are attempting to solve.
This sentiment is echoed in the security space, where analysts, operators, and detection engineers have a natural skepticism toward AI tooling, even more so when applied to LLM code generation. There's a prevailing, yet understandable concern that these tools output "plausible-sounding nonsense", not valuable detections. An LLM agent can generate a syntactically perfect rule that is logically flawed, easily bypassed, or prone to false positives (FPs) on benign behavior, creating a burst of noisy alerts.
This is why evals and benchmarks are valuable. They represent the "verify" in "trust but verify." In our scenario, evals provided the framework necessary to measure and ultimately prove that a generated rule is not only syntactically correct but also efficient, robust, and effective. Recognizing that the current set of code generation evals would only produce noise for our use case, we built a framework (fully detailed in our ArXiv preprint, which we will be presenting at CAMLIS 2025 later this year) tailored to the single question we care about: Can an AI agent craft detection rules that actually protect and augment our customers?
Our North Star: A three-pillar framework for measuring performance
We ship rules that reduce real risk without adding noise or operational drag. To measure this, every rule is assessed against three pillars: Detection Accuracy, Robustness, and Economic Cost. This framework moves the conversation from subjective impressions of plausibility to objective, quantifiable data.
1. Detection Accuracy
A rule earns its place when it addresses real attacks and fills gaps in our portfolio. We report Precision (the percentage of all matches that were truly malicious), Unique True Positives (malicious events that this rule alone identified), and Net-New Coverage (the additional share of a known campaign we catch when this rule runs alongside our existing detections). In a live security environment, accurately calculating recall is often impossible because the total universe of malicious events is unknown. Net New Coverage serves as a practical and powerful proxy, measuring the marginal value a new rule adds to our overall defense.
2. Robustness
As attackers manipulate inputs, good rules should not break. We summarized a rule's resistance to adversarial inputs with the Robustness score. This score seeks to derive a rule's brittleness by analyzing the detection rule's abstract syntax tree (AST). The algorithm assigns higher weights to rule logic that describes attacker behaviors over simple string matching. Conversely, it penalizes an over-reliance on the use of brittle Indicators of Compromise (IOCs), such as specific IP addresses, file hashes, or hardcoded strings.
Unlike typical “rules” that are simple to evade, Sublime’s MQL, the DSL that underpins our detection system, is feature rich and can describe attacks behaviorally using AI-powered enrichment functions such as NLU, Computer Vision, historical behavior, and even risk scoring functions using traditional ML models to detect never before seen techniques beyond known permutations.
While the Robustness score provides a useful comparative metric for human-written detections, we acknowledge its limitations. Mainly, our current approach relies on static analysis rather than dynamic testing against actual evasion attempts. We are working on incorporating adversarial inputs to conduct more comprehensive testing and validate these scores. Still, this metric has consistently proven valuable, as it surfaces rules and logic that will likely require frequent updates, as opposed to those that generalize to specific behaviors over time.
3. Economic Cost
Ultimately, great detections must still be affordable to create and operate. We track pass@k → cost-to-pass (how many generations to a valid rule and the cost to get there), time-to-production (generation → review → deploy), and runtime cost per 1k messages. These metrics quantify the efficiency gains from AI, providing the business case for augmenting human experts. By lowering the cost and time for tactical rule generation, we free up our senior engineers for strategic work like novel threat research and proactive hunting.
What is pass@k? pass@k is the chance that, if an agent makes k attempts, at least one is valid. We pair pass@k with cost-to-pass (the actual dollars spent to achieve a valid rule), so teams can judge speed and spend, not just success in the abstract.
Putting theory into practice: Deconstructing an AI-generated rule
Using the above framework, we can see how Sublime’s Autonomous Detection Engineer (ADÉ) performs compared to a human detection engineer. Let’s start with the construction of the rule:
- Section 1: The Vector. The agent correctly identifies the core delivery mechanism, an attached email containing an embedded SVG. The agent recognizes that SVGs can be used to embed and execute malicious JavaScript, making them an increasingly attractive vehicle for smuggling attacks.
- Section 2: The Technique. It looks for evidence of obfuscation by scanning for Base64-encoded content and inspecting decoded payloads for keywords associated with malicious JavaScript. This demonstrates an understanding of the primary tactics, techniques, and procedures (TTPs) associated with smuggling.
- Section 3: The Targeting. It adds another behavioral check: does the smuggled file contain the recipient's own email address? This is a classic social engineering technique used to present a tailored landing page for the recipient and increase the legitimacy of the payload. This shows the agent is reasoning about attacker intent, not just technical artifacts.
- Section 4: The Context. Finally, it synthesizes this evidence with contextual signals about the sender's reputation, checking for high-risk attributes and DMARC failures. This mirrors the process gleaned from human detection engineers, who apply a set of best practices to reduce the likelihood of false positives in production.
The result is not a simple, IOC-based rule; rather, it is a sophisticated behavioral detection that synthesizes evidence from the target message, its prompt, and a deep domain knowledge base.

The verdict: From plausible to provable with ADÉ
When we compared a holdout set of ADÉ-generated rules against their human-authored counterparts, the results were nuanced. Human rules, written with a broader context, generally had higher recall. ADÉ-generated rules were often crafted from a single example message, resulting in a rule that was often more surgical, achieving near-perfect precision. This highlights a key strength of the AI: closing detection gaps quickly with high-precision rules, surfacing new signals for behavioral ML, and reducing Mean Time to Detect (MTTD) for a given organization.

Holdout testing against the Sublime Core Feed allows us to compare apples to oranges fairly: one-sample AI rules versus broad human rules.
Similarly, ADÉ-generated rules achieved robustness scores that were on par with those written by our human detection engineers, providing a strong indication that rules generated by ADE would not require frequent updates or be easily circumvented by simple adversarial techniques, such as string manipulation.
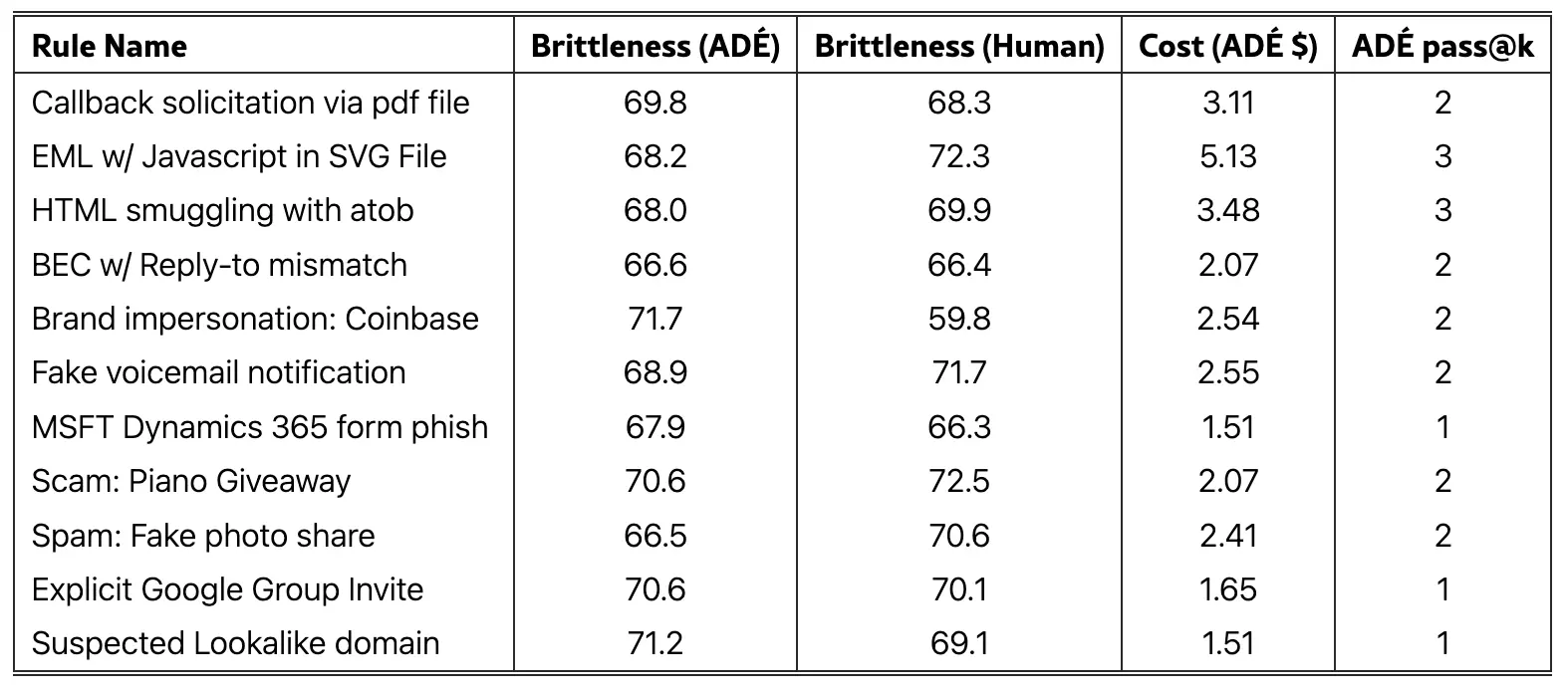
In terms of economic efficiency, pass@k shows that ADÉ reaches a valid rule in just a few tries while keeping the spend predictable – the median cost-to-pass rises from about $1.5 at k=1 to roughly $4.3 at k=3. We use that metric to learn an optimal ADÉ retry policy and establish early-exit criteria. We then use the per-attempt traces surface, where failures cluster (validation vs. quality), to determine if we need to add new test cases or make adjustments to tool access, knowledge base, or prompts, thereby achieving a goal of driving down cost and time-to-production over successive runs.
Framework for continuous improvement
The most exciting aspect of this framework is its ability to evolve in tandem with our agent. As ADÉ grows in sophistication, this evaluation can grow with it. Bringing in adversarial robustness testing will be critical in teaching ADÉ how to write rules that generalize, rather than relying on brittle logic. We aim to expand beyond binary malicious/benign classification to address spam and graymail, recognizing that these are daily challenges for all organizations.
So while this framework may never be "done", it is already providing what we needed the most: consistent, repeatable metrics to capture whether adjustments to our prompt, knowledge base, or model actually improve ADÉ for our customers.
AI that hardens coverage
While the debate over AI's role in security is certainly not over, we have shown our approach to agentic detection engineering moves the needle beyond being a stochastic parrot or "plausible nonsense." Not because we claim it, but because we now have frameworks to measure their performance. This eval lets ADÉ close gaps fast with high-precision rules – and it feeds those outcomes back into our behavioral machine learning, so coverage doesn’t just patch, it learns and hardens over time.
We believe frameworks like this enable vendors to evaluate agents against realistic scenarios and practical metrics, fostering transparency and cultivating customer trust.
For a deep dive into the evaluation framework, agent architecture, and full results, we invite you to read our paper, "Evaluating LLM-Generated Detection Rules in Cybersecurity," available on ArXiv. Dr. Anna Bertiger (Machine Learning Researcher at Sublime) will also be presenting this work at the Conference on Applied Machine Learning in Information Security (CAMLIS) on Thursday, October 23, and we welcome you to join the debate on the future of AI in detection engineering.
Get the latest
Sublime releases, detections, blogs, events, and more directly to your inbox.
.svg)



.avif)
